
Back To Base (Make SQL Great Again)
I have to admit upfront that my brain is somehow incompatible with JPA. Every time
I try to use JPA, I will somehow wind up fighting weird issues, be it
LazyInitializationException with Hibernate, or weird sequence generator preallocation
issues with EclipseLink. I don’t know what to use merge() for; I lack the means
to reattach a bean and overwrite its values from the database.
I don’t want to bore you to death with all of the nitty-gritty details; all the reasons are summed in Issue #3 Remove JPA. I think that the number 1 reason of why JPA is incompatible with me is that: JPA is built around the idea that the Java classes, not the database, is the source of truth.
The Source Of Truth
When you have a SQL database, that database is your primary and only storage of data. Every time you need to get data, you go to that database, you don’t go anywhere else. You may cache the data temporarily, or mirror the database (akin to Master-Slave in MySQL); however, when in doubt (e.g. you suspect that the cache might be stale), you go to the database to see the actual, correct and up-to-date data. The database is the authority for data. It is the source of truth.
The JPA works the other way around. The data stored in the in-memory JPA entities is the source of truth. You call a getter on the JPA entity when you need the most up-to-date data. You do not go to the database itself: the database is just an implementation detail, simply a way to store the data while the server is down. Of course, you can not load entire database into memory, but the Entity Manager tries to create an abstraction that you can: it loads the entity if it’s not in memory yet, then it listens for changes in the entity and eventually updates the data in the database. The Entity Manager creates an abstraction that the beans are the source of truth.
The idea is that you always go through the Entity Manager, and never directly into the SQL database.
That’s why there’s no reload() function to update entity with data from the database -
that goes against the entire principle of beans being the source-of-truth: why
would you update the source-of-truth entity from some data dump? That’s why JPA is free
to ignore changes done in the database from outside of Entity Manager - you have
to completely disable JPA cache to actually see the changes.
If I want the database to be the source of truth and still want to use JPA, I’m going to suffer a lot: I’ll have to fight the JPA API constantly.
JPA: The Object Database way
To allow Java beans to be the source of truth, JPA defines certain techniques and requires Hibernate to sync Java beans with the database behind the scenes. That is unfortunately a non-trivial issue which cannot be done automatically in certain cases, and that’s why JPA abstraction suffers from the following issues:
- Hibernate must track changes done to the bean, in order to sync them to the underlying
database. That is done by intercepting all calls to setters, which can only be done by
runtime class enhancement (for every entity Hibernate creates a class which extends that
entity, overrides all setters and injects some Hibernate core class which is notified of
changes). Such class can hardly be called a POJO since passing that class around will
start throwing
LazyInitializationExceptionlike hell. That is the black magic, pure and evil. - It intentionally lacks the method to reattach a bean and overwrite its contents with the database contents - this goes against the idea of having Java class the source of truth.
- By abstracting joins into Collections, it causes the programmers to unintentionally write code which suffers from the 1+N loading issues.
I see the following issues with the entities being the source of truth:
- My mindset is that the database is the source of truth
- I don’t want to use an object database; I want to use a SQL database
- I don’t want to use half-assed object database that heavily leaks the fact that it’s running on SQL storage
- I don’t want to use loads of black magic employed by Entity Manager to track changes
Since I’m very bullheaded, instead of trying to attune my mind towards JPA I explored the different approach: let’s step back and make the database the source of truth again.
Database As The Source Of Truth
Having Database as the source of truth means that the data in your bean may be obsolete the moment it leaves the database (since there might be somebody else already modifying that thing). The optimistic/pessimistic locking is the way around that, and to have the most recent data you will need to requery from the database.
The bean can now ditch all of its sync capabilities and become just a snapshot: a sample of the state of the database row at some particular time. Changes to the bean properties will no longer be propagated automatically to the database, but need to be done explicitly by the developer. The developer is once again in charge.
There - I have solved the whole detached/managed/lazy initialization exception nonsense for you :-)
The beans are once again POJOs with getters and setters, simply populated from the database by reading the data from the JDBC
ResultSetand calling bean’s setters.
That can be achieved by a simple Java reflection. Moreover, no runtime enhancement
is needed since the bean will never track changes; to save changes we will need to
issue the INSERT/UPDATE statement. Also, since there’s no
runtime enhancement, the bean is really a POJO and can be actually made serializable
and passed around in the app freely, which means that you don’t need DTOs anymore.
vok-orm
There is a very handy library called JDBI which maps
JDBC ResultSet to Java POJOs and nothing more.
This idea forms the very core of vok-orm (Kotlin)
and jdbi-orm (Java).
To explain the data retrieving capabilities of the vok-orm library,
let’s begin by implementing a simple function which finds a bean by its ID.
vok-orm: Data Retrieval From Scratch
The findById() function will simply issue a select SQL statement which selects
a single row, then passes it to JDBI to populate the bean with the contents of that row:
fun <T : Any> Connection.findById(clazz: Class<T>, id: Any): T? =
createQuery("select * from ${clazz.databaseTableName} where id = :id")
.addParameter("id", id)
.executeAndFetchFirst(clazz)
The function is rather simple: it is actually nothing more but a simple Kotlin
reimplementation of the very first example in the JDBI.
The JDBI API will do nothing more but create a JDBC PreparedStatement, run it,
create instances of clazz using the zero-arg constructor,
populate the bean with data and return the first one. Using this approach it is
easy to implement more of the finders, such as findAll(clazz: Class<T>),
findBySQL(clazz: Class<T>, where: String). However, let’s focus on the findById() for now.
To obtain the JDBI’s Connection (which is a wrapper of JDBC’s connection),
we simply poll the HikariCP connection pool and use the db{} method to start+commit
the transaction for us. This will allow us to retrieve beans from the database easily,
simply by calling the following statement from anywhere of your code, be it a
background thread, or a Vaadin button click listener:
val person: Person = db { connection.findById(Person::class.java, 25L) }
This is nice, but we can do better. In the dependency injection world, for every
bean there is a Repository or DAO class which defines such finder methods and
fetches instances of that particular bean. However, we have no DI and therefore
we do not have to have a separate class injected somewhere, just for the purpose
of accessing a database. We are free to attach those finders right where they
belong: as factory methods of the Person class:
class Person {
companion object {
fun findById(id: Long): Person? = db { connection.findById(Person::class.java, id) }
}
}
This will allow us to write the finder code even more concise:
val person = Person.findById(25L)
Yet, adding those pesky findById() (and all other finder methods such as findAll())
manually to every bean is quite a tedious process. Is there perhaps some easier,
more automatized way to add those methods to every bean? Yes there is, by the means of mixins and companion objects.
As a first attempt, we will define a Dao interface as follows:
open class Dao<T>(val clazz: Class<T>) {
fun findById(id: Any): T? = db { connection.findById(clazz, id) }
}
Remember that the companion object is just a regular object, and as such it can extend classes?
class Person {
companion object : Dao<Person>(Person::class.java)
}
This allows us to call the finder method as follows:
val person = Person.findById(25L)
vok-orm follows this idea and provides the Dao interface for you, along
with several of utility methods for your convenience. By the means of extension methods,
you can define your own global finder methods, or you can simply attach finder methods to your beans as you see fit.
You can even define an extension property on Dao which produces Vaadin’s DataProvider,
fetching all instances of that particular bean. Luckily, you don’t have to do
that since vok-orm already provides one for you.
Next up, data modification.
vok-orm: Data Modification
Unfortunately JDBI doesn’t support persisting of the data, so we will have to
do that ourselves. Luckily, it’s very simple: all we need to do is to generate
a proper insert or update SQL statement:
interface Entity<ID: Any> : Serializable {
...
fun save() {
db {
if (id == null) {
// not yet in the database, insert
val fields = meta.persistedFieldDbNames - meta.idDbname
con.createQuery("insert into ${meta.databaseTableName} (${fields.joinToString()}) values (${fields.map { ":$it" }.joinToString()})")
.bind(this@Entity)
.executeUpdate()
id = con.key as ID
} else {
val fields = meta.persistedFieldDbNames - meta.idDbname
con.createQuery("update ${meta.databaseTableName} set ${fields.map { "$it = :$it" }.joinToString()} where ${meta.idDbname} = :${meta.idDbname}")
.bind(this@Entity)
.executeUpdate()
}
}
}
...
}
Simply by having your beans implement the Entity interface, you will gain the ability to save and/or create database rows:
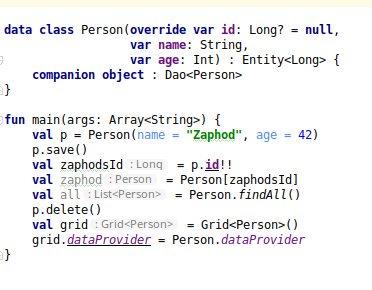
data class Person(override var id: Long, var name: String): Entity<Long> {
companion object : Dao<Person>
}
val person = Person.findById(25L)
person.name = "Duke Leto Atreides"
person.save()
Pure simplicity:
Wrap-up
JPA is an object database on top of relational database, which everyone uses as a relational database in the first place. It’s the mother of all leaky abstractions which is not even used properly; I’d even argue that it’s impossible to be used properly. Avoid and use literally anything else: JOOQ, vok-orm (or jdbi-orm if Java is your thing), ActiveJDBC, JDBI directly.