
The Grid and the problem of broken equals()/hashCode()
You may already have encountered a funny “bug” when using Vaadin Grid:
- Vaadin Grid shows one row repeatedly, even though the list clearly contains beans with different values.
- When I select one item in a grid, multiple rows are suddenly selected for no apparent reason.
Both issues are caused by a funny implementation of hashCode()/equals() in your bean.
Say that you have the following bean:
public class Person implements Serializable {
public String name;
public Person(String name) {
this.name = name;
}
@Override
public boolean equals(Object obj) {
return true; // clearly broken, don't do this
}
@Override
public int hashCode() {
return 1; // clearly broken, don't do this
}
}
And you have the following view:
@Route("")
public class MainView extends VerticalLayout {
public MainView() {
final Grid<Person> grid = new Grid<>();
grid.addColumn(it -> it.name);
grid.setItems(new Person("Jim"), new Person("Martin"), new Person("Albert"));
grid.asSingleSelect().setValue(jim);
add(grid);
}
}
This view will render a random name repeatedly; moreover all rows will appear selected even though the Grid is clearly configured as single-select!
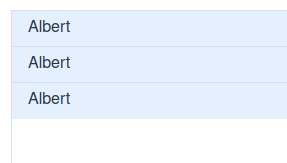
The problem is closely tied to how Grid works internally, and is not easy to spot at first sight. Let’s take a look.
How Grid Sends Data To Client-Side
In order to show the data in the browser, Grid needs to transfer the data to the client, as a JSON. The grid can’t simply take a List of Java objects, serialize it to bytes using Java Serialization and pass it to the browser, there are numerous issues with that approach:
- The object may not be serializable
- JavaScript can’t simply de-serialize objects serialized by Java. (it’s actually possible to implement such algorithm, but it’s definitely a bad idea, because of the next item)
- We could expose more than we want. Say that the
Personcontains ahashedPasswordfield (or worse, a plain-textpasswordfield). - Also: formatting; which column would show which bean property, etc.
Therefore, when Grid needs to display a row in the browser, Grid will run all ValueProviders for every
column, convert that to List<String> and send that to the client-side, one for every row. Actually Grid sends rows in batches,
so it will send a List<List<String>> instead. Actually scratch that, Grid will send a Map<ID, List<String>>
instead. The ID is a very important point here.
Essentially, Grid refers to individual rows by their IDs. Why not by their indices? After all, we fetch rows from given offset, then pass it to the grid. At the time of fetching, we know the index of the row. So why not use the row indices as IDs? A very good question.
After the rows are sent to the client-side, it’s no longer possible to
learn the index just from a Person instance alone. Why do we need that? Because of selection. But we digress.
Let’s return to this topic later on. For now you’ll have to just accept that Grid can’t use row_index and
needs to invent IDs instead, one for every row.
Item IDs
Server-side Grid therefore needs to calculate an ID for every bean being displayed.
It uses a very simple approach: the KeyMapper class maps bean instance to an auto-generated integer,
then passes only that integer to the client-side. KeyMapper uses HashMap internally…. AHA!
The conversation between Grid and KeyMapper goes like this:
- Grid: KeyMapper, do you have an ID for
Person("jim")please? - KeyMapper: Not yet; but I’ve stored the
Personinstance to myHashMapwith an ID I just generated for it (an integer with the value of1); here’s the ID. - Grid: Thanks! I’ll run the
ValueProviders, I’ll render “jim” for my column and I’ll send “jim” along with the ID of 1 to the client-side. What aboutPerson("martin")? - KeyMapper: Yes, my
HashMapalready containsPerson("martin")and the ID is1, here it is. - Grid: Ah great, alright, I’ll pass “martin” with the ID of 1 to the client-side. Hmm, strange, there’s already something under the ID of 1 in my list of instructions heading client-side… whatever I’ll just overwrite. What about
Person("albert")? - KeyMapper: Yes, my
HashMapalready containsPerson("albert")and the ID is1, here it is. - Grid: alrighty, writing down “albert” under ID 1.
The grid will thus send three identical rows to the client-side; in JSON communication from server to client it will look something like this:
[{"id": 1, "values": ["Albert"]}, {"id": 1, "values": ["Albert"]}, {"id": 1, "values": ["Albert"]}]
And we have arrived to the core of the problem. Clearly KeyMapper is lying like crazy here, but that’s because the Person.equals()/hashCode() has broken
the contract as required by HashMap which causes HashMap to fail to work properly.
The Problem of the Grid Selection
Selected rows in the Vaadin Grid are internally represented as a Set of Person. And you should already hear an alarm bell:
never place objects with broken equals()/hashCode() into a Set. True, but let’s take a look what exactly happens.
What will happen in grid.asSingleSelect().setValue(jim); is that Vaadin will create a Set holding just one item: jim,
and will store that as a selection, then it will pass it to the client-side.
We can’t pass in Persons directly to the client-side, we know that already.
We unfortunately can not calculate the row index only from the Person instance alone.
That is the primary reason why Grid uses the ID mechanism and the KeyMapper instead of row indices.
What Grid will do is that it will turn Set<Person> into a List<Integer>
containing IDs of selected beans, then it will pass it down to the client-side.
The client-side is already displaying three identical rows with ID of 1, and is told to
select all rows with IDs of 1. Therefore, it will select all rows.
Solutions
Now that we know how the ID/row Grid mechanism work, let’s take a look at possible solutions, and possible
implementations of hashCode()/equals().
The ‘Data Class’ Solution
Data class simply calculates equals()/hashCode() from the value of its fields.
We only have one field, therefore we’ll fix the code as follows:
public class Person implements Serializable {
@Override
public boolean equals(Object obj) {
return obj instanceof Person && ((Person) obj).name.equals(name);
}
@Override
public int hashCode() {
return name.hashCode();
}
}
This makes sense: new Person("Jim").equals(new Person("Jim")) should obviously hold true.
This fixes the Grid example and the selection, but opens up a very interesting corner-case problem: say that you want to clone a person in the grid. A “clone” button will take the currently selected item, add it to the list and set it to the grid. Say that the list of items in the Grid now reads
new Person("Jim"), new Person("Martin"), new Person("Albert"), new Person("Jim")
We select “the other” Jim to try to edit his name, however both Jims get selected, and we don’t know which instance of Jim we are about to edit!
The simplest workaround is to add a new Person("Jim (Clone)") instead, or Jim #2 or similar.
This makes sense: if your Grid shows Jim two times, your user will also have a hard time differentiating between those two.
This is the bean “identity” problem; discussion on this topic is beyond the scope of this article.
The Database Entity (JPA) solution
For an entity fetched from a backend system you should employ a different strategy. Usually you have a primary key identifier of the record; read JPA Entity Equality for more info. In short, the entities are supposed to represent a row with given ID anyway; if they represent the same row then they’re equal, regardless of what data they hold. They might have been retrieved at different times, with a data modification in between.
The algorithm is as follows:
- If both entities have non-null primary keys, compare those only and ignore differences in values.
- If both entities have null primary keys, compare as data class - all of their properties. That will leave the clone problem open though. Read below on how to solve the clone problem.
System.identityHashCode()
Alternatively, we could simply delete Person.equals()/hashCode() and leave Object to calculate those,
using System.identityHashCode(). That will make new Person("Jim").equals(new Person("Jim")) return
false (which looks weird), but at least the user will be able to select “the other Jim”
independently of the “original Jim” and edit it.
This may work when you have data in-memory, but quickly falls apart when you have data loaded from a database.
Say you want to select a person by his name, “Jim”. You run a SQL SELECT to fetch a bean from a database,
then proceed to call grid.asSingleSelect().setValue(person); to select the person, only to find out
that nothing is selected at all. The problem is that the new person has received a new ID by the KeyMapper
(because it’s a new instance of the Person class which isn’t equal to the old one).
In other words, the Grid shows rows with IDs of 1, 2 and 3, and you’re telling the Grid to select row with ID 4.
No One-Size-Fits-All Solution
It appears that there’s a fundamental problem here: you will have to make some objects equal in order for a selection-from-backend scenario to work, which will break the clone scenario.
You will have to choose one, based on the usage scenario.
Basically, by default it’s best to use the Data/JPA equality solution and work around the ‘clone’ problem.
However, sometimes you don’t have that kind of possibility, and you have to use the identityHashCode() solution.
The identityHashCode() solution will work well when:
- All data is in-memory;
- or if the Grid will not allow for a selection (
SelectionMode.NONE); - or if only the user will perform selection changes (the server is not trying to set a new selection)
Solving the ‘clone’ problem
To solve the ‘clone’ problem, you can rework your UX, edit the newly created row in a new dialog and only
show the row in the grid after it is persisted in the database.
Alternatively, you can make the clone unique by adding " (Clone #1)" to its name or similar.
If you can’t change equals()/hashCode()
Sometimes the entities come from a legacy JAR and there’s nothing you can do about their
hashCode()/equals() without risking that the legacy code falls apart. Is there another way perhaps?
DataProvider.getId()
There is a way to tell Grid to map the entity to an ID using a different approach, by overriding the DataProvider.getId().
The Bean-to-ID translation goes as follows:
- Grid asks
DataProvider.getId()to obtain an “ID” from a bean. By default, theDataProvidersimply returns the bean itself. - Grid then takes this “ID”, goes to
KeyMapperand translates it to an Integer ID which is then used in Grid server-client communication.
You can override DataProvider.getId() and use any of the strategy above, to fix the grid formatting issue.
However, the multi-select grid will still stuff the beans themselves into a Set, continuing to use the bean’s
broken hashCode()/equals() implementation underneath. Therefore,
this fix won’t work with multi-select Grid (even though it will work with single-select Grid).
Wrapper class
You can create a Wrapper class which wraps your bean and calculates hashCode()/equals() properly.
The problem is that instead of having Grid<T> you’ll have Grid<Wrapper<T>>, which
brings a lot of complexities down the road:
- The
DataProviderneeds to be modified to returnWrapper<T>instead ofT - All column formatters and
ValueProviders must acceptWrapper<T>instead ofTas their parameters - To read/write the selection, you need to wrap/unwrap
Set<Wrapper<T>>intoList<T>(remember the brokenhashCode()/equals()) constantly. - When using Grid’s editor, binding
Wrappervia a binder is more tricky.
Because of these annoyances, we don’t recommend this pattern.
DTOs
You can copy all the data from the backend beans to your own DTO classes which you fully control, and then pass those DTOs around
public class PersonDTO implements Serializable {
public String name;
public Person(String name) {
this.name = name;
}
@Override
public boolean equals(Object obj) {
return obj instanceof PersonDTO && ((PersonDTO) obj).getName().equals(getName());
}
@Override
public int hashCode() {
return getName().hashCode();
}
public static PersonDTO from(Person person) {
return new PersonDTO(person.getName());
}
public Person toPerson() {
return new Person(name);
}
}
This is the cleanest approach: the UI layer simply always uses DTOs - the original beans are not used at all,
and all ValueProviders simply work with DTOs from the beginning. There are no Wrappers or anything like that -
all DataProviders, ValueProviders and Binders operate directly on the DTOs. You can also add
validation annotations to the DTOs, then using BeanValidatingBinder which makes validations a breeze.
The downside is that you’re essentially duplicating all of your backend beans - for every database table a DTO needs to be written, and a code converting the bean to DTO and back needs to be written and maintained as well.
Extending the original bean
You’ll introduce a FixedPerson class which extends the original Person class and fixes hashCode()/equals():
public class FixedPerson extends Person {
@Override
public boolean equals(Object obj) {
return obj instanceof FixedPerson && ((FixedPerson) obj).getName().equals(getName());
}
@Override
public int hashCode() {
return getName().hashCode();
}
public static FixedPerson from(Person person) {
return new FixedPerson(person.getName());
}
}
You’ll still need to modify the DataProvider to serve FixedPersons instead of Persons, but
you don’t have to convert the selection anymore, and all existing ValueProviders will happily continue to
work as expected - the advantage over the Wrapper pattern is clear. Also, since FixedPerson is a Person as well,
you may not have to convert FixedPerson to a Person as it is with the DTO approach.
However, this may not work with JPA though - JPA managed beans may be proxy classes,
dynamically created from Person in order to track the changes, but this is beyond
the scope of this article.